Toronto Homeless Shelters
Jim Gruman
December 1, 2020
Last updated: 2021-09-08
Checks: 7 0
Knit directory: myTidyTuesday/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210907) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 836521b. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: catboost_info/
Ignored: data/2021-09-08/
Ignored: data/acs_poverty.rds
Ignored: data/hike_data.rds
Ignored: data/us_states.rds
Ignored: data/weatherstats_toronto_daily.csv
Unstaged changes:
Modified: code/_common.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/TorontoShelters.Rmd) and HTML (docs/TorontoShelters.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 836521b | opus1993 | 2021-09-08 | apply theme_jim() |
The data this week comes from Sharla Gelfand’s opendatatoronto R package. Her website has additional details and all sorts of other great datasets.
We are going to explore many of the time series aspects of Homelessness in Toronto, overlay the daily weather, and finally attempt to model and infer what drives the occupancy rate.
suppressPackageStartupMessages({
library(tidyverse)
library(lubridate)
library(hrbrthemes)
extrafont::loadfonts(quiet = TRUE)
library(treemap)
library(tidymodels)
})
source(here::here("code","_common.R"),
verbose = FALSE,
local = knitr::knit_global())
ggplot2::theme_set(theme_jim(base_size = 12))tt <- tidytuesdayR::tt_load("2020-12-01")
Downloading file 1 of 1: `shelters.csv`ttAn initial look at the format of the dataset provided:
tt %>%
map(glimpse)Rows: 115,916
Columns: 13
$ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,~
$ occupancy_date <dttm> 2017-01-01, 2017-01-01, 2017-01-01, 2017-01-01, 2~
$ organization_name <chr> "COSTI Immigrant Services", "Christie Ossington Ne~
$ shelter_name <chr> "COSTI Reception Centre", "Christie Ossington Men'~
$ shelter_address <chr> "100 Lippincott Street", "973 Lansdowne Avenue", "~
$ shelter_city <chr> "Toronto", "Toronto", "Toronto", "Toronto", "Toron~
$ shelter_province <chr> "ON", "ON", "ON", "ON", "ON", "ON", "ON", "ON", "O~
$ shelter_postal_code <chr> "M5S 2P1", "M6H 3Z5", "M6H 3Z5", "M6G 3B1", NA, "M~
$ facility_name <chr> "COSTI Reception Centre", "Christie Ossington Men'~
$ program_name <chr> "COSTI Reception Ctr CITY Program", "Christie Ossi~
$ sector <chr> "Co-ed", "Men", "Men", "Families", "Men", "Familie~
$ occupancy <dbl> 16, 13, 63, 66, 58, 168, 119, 23, 8, 14, 0, 0, 173~
$ capacity <dbl> 16, 17, 63, 70, 60, 160, 150, 28, 0, 40, NA, 0, 25~$shelters
# A tibble: 115,916 x 13
id occupancy_date organization_name shelter_name shelter_address
<dbl> <dttm> <chr> <chr> <chr>
1 1 2017-01-01 00:00:00 COSTI Immigrant Se~ COSTI Receptio~ 100 Lippincott~
2 2 2017-01-01 00:00:00 Christie Ossington~ Christie Ossin~ 973 Lansdowne ~
3 3 2017-01-01 00:00:00 Christie Ossington~ Christie Ossin~ 973 Lansdowne ~
4 4 2017-01-01 00:00:00 Christie Refugee W~ Christie Refug~ 43 Christie St~
5 5 2017-01-01 00:00:00 City of Toronto Birchmount Res~ 1673 Kingston ~
6 6 2017-01-01 00:00:00 City of Toronto Birkdale Resid~ 1229 Ellesmere~
7 7 2017-01-01 00:00:00 City of Toronto Birkdale Resid~ 1229 Ellesmere~
8 8 2017-01-01 00:00:00 City of Toronto Downsview Dells 1651 Sheppard ~
9 9 2017-01-01 00:00:00 City of Toronto Family Residen~ 4222 Kingston ~
10 10 2017-01-01 00:00:00 City of Toronto Family Residen~ 4222 Kingston ~
# ... with 115,906 more rows, and 8 more variables: shelter_city <chr>,
# shelter_province <chr>, shelter_postal_code <chr>, facility_name <chr>,
# program_name <chr>, sector <chr>, occupancy <dbl>, capacity <dbl>The dataset appears to be a daily report-out of every facility’s occupancy and capacity.
Let’s grab the weather too
Importing climate daily stats from “https://toronto.weatherstats.ca/download.html”
weather <- read_csv(here::here("data/weatherstats_toronto_daily.csv")) %>%
select(date, max_temperature, min_temperature, avg_temperature, precipitation)Some fields in the shelter data need be cast as integers and dates. We will also impute to fill-in missing capacity figures on the daily reports, where possible
shelters <- tt$shelters %>%
mutate(across(occupancy:capacity, as.integer),
occupancy_date = lubridate::as_date(occupancy_date)
) %>%
group_by(facility_name, shelter_name, organization_name) %>%
fill(capacity, .direction = "downup") %>%
ungroup()Some basic facts about Toronto’s homeless shelter network
The network consists of 33 organizations with 65 named shelters with 114 individual facility locations. Some sites host families, some men, and some women.
shelters %>%
filter(!is.na(capacity)) %>%
group_by(facility_name) %>%
summarize(
max_cap = max(capacity, na.rm = TRUE),
.groups = "drop"
) %>%
slice_max(order_by = max_cap, n = 10) %>%
mutate(facility_name = fct_reorder(facility_name, max_cap)) %>%
ggplot(aes(max_cap, facility_name)) +
geom_col(aes(fill = facility_name),
show.legend = FALSE
) +
labs(
title = "Toronto's Largest Homeless Shelter Facilities",
subtitle = "The Radisson has 902 beds",
x = "Capacity each Night", y = "",
caption = "Data: open.toronto.ca | Visual: jim_gruman"
) +
theme(panel.grid.major.y = element_blank())
Some of the largest shelters appear to be re-purposed hotel facilities.
For reference, let’s sum the maximum bed capacity at all facilities for a perspective of the total network capacity:
shelters %>%
filter(!is.na(capacity)) %>%
group_by(facility_name) %>%
summarize(
max_cap = max(capacity),
.groups = "drop"
) %>%
summarise(Total_Capacity = sum(max_cap, na.rm = TRUE))# A tibble: 1 x 1
Total_Capacity
<int>
1 9282There may have been some facility name changes, because the detail by month does not support this grand total.
Typical facilities are under 200 beds
shelters %>%
ggplot() +
geom_histogram(aes(capacity), fill = 2) +
labs(
title = "Capacity Range of Facilities in Toronto's Homeless Shelter System",
subtitle = "Some of the largest shelters appear to be re-purposed hotel facilities.",
y = "Number of Facilities",
x = "Bed Capacity",
caption = "Data: open.toronto.ca | Visual: jim_gruman"
)
shelter_cap <- shelters %>%
filter(capacity > 0) %>%
group_by(organization_name, shelter_name, facility_name) %>%
summarize(
capacity = max(capacity, na.rm = TRUE),
.groups = "drop"
)
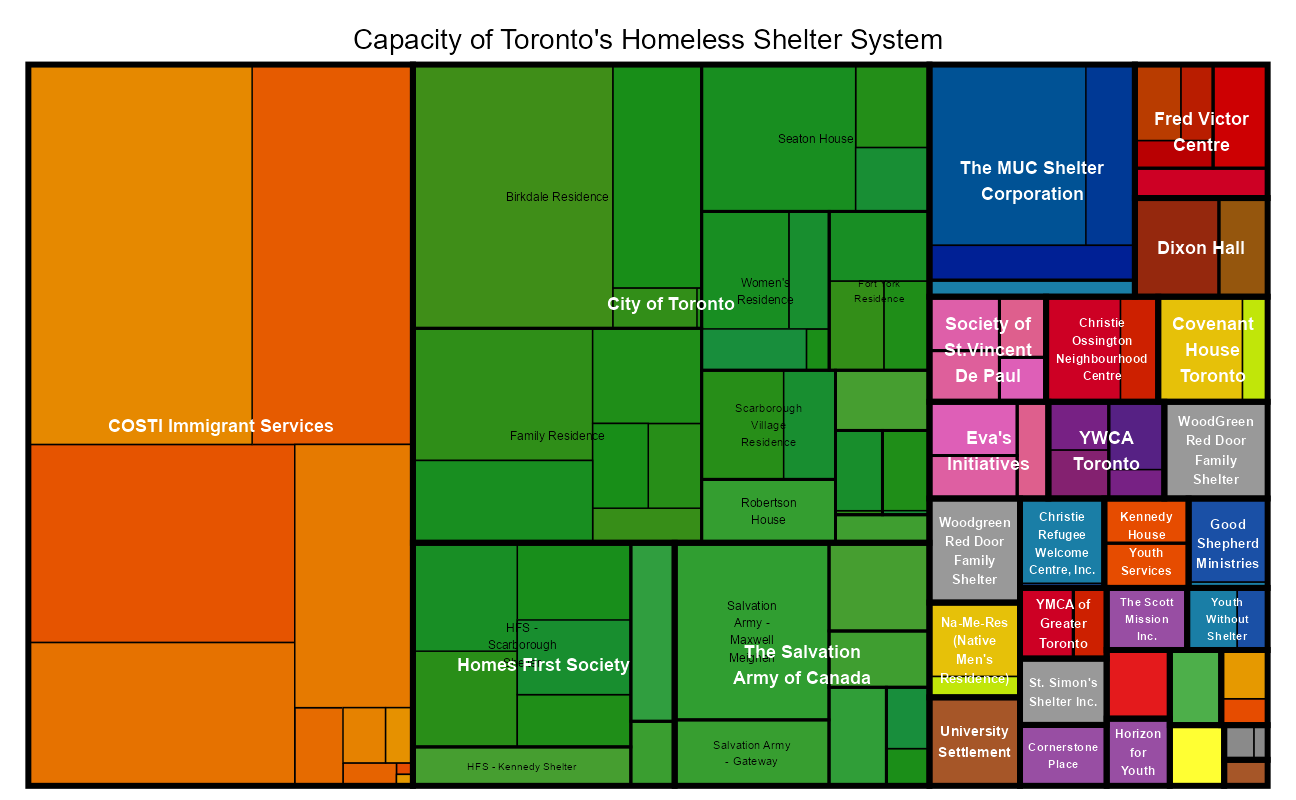
treemap(shelter_cap,
index = c(
"organization_name",
"shelter_name",
"facility_name"
),
vSize = "capacity", type = "index",
fontsize.labels = c(9, 6, 4),
fontcolor.labels = c("white", "black", "black"),
bg.labels = c("transparent"),
palette = "Set1",
title = "Capacity of Toronto's Homeless Shelter System"
)
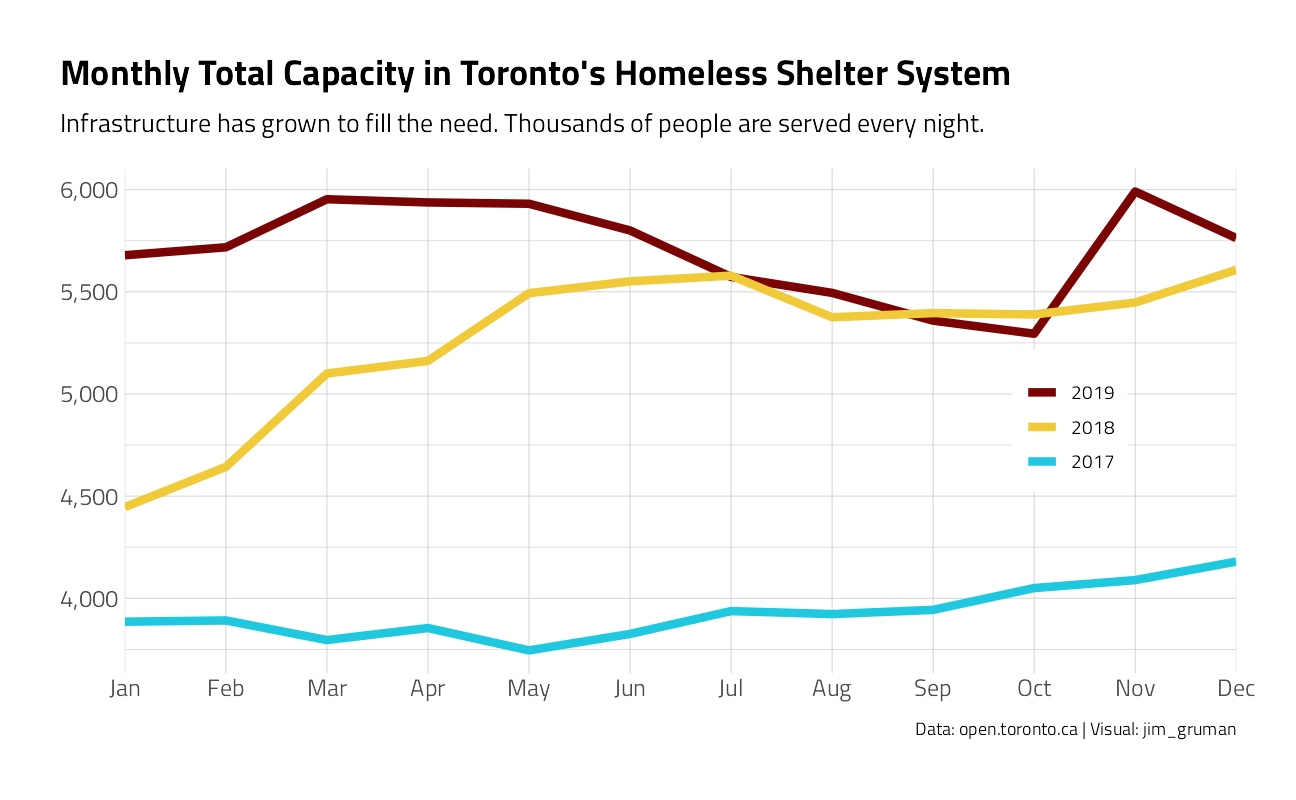
Let’s look at capacity across the network, by month, over time:
shelters %>%
group_by(
month = month(occupancy_date,
abbr = TRUE,
label = TRUE
),
year = factor(year(occupancy_date),
levels = c("2019", "2018", "2017")
),
facility_name
) %>%
summarize(
avg_cap = mean(capacity, na.rm = TRUE),
.groups = "drop_last"
) %>%
summarize(
tot_cap = sum(avg_cap, na.rm = TRUE),
.groups = "drop"
) %>%
ggplot(aes(month, tot_cap, color = year, group = year)) +
geom_line(size = 2) +
scale_y_continuous(label = scales::comma_format()) +
scale_x_discrete(expand = c(0, 0)) +
labs(
title = "Monthly Total Capacity in Toronto's Homeless Shelter System",
subtitle = "Infrastructure has grown to fill the need. Thousands of people are served every night.",
y = NULL, color = NULL,
x = NULL,
caption = "Data: open.toronto.ca | Visual: jim_gruman"
) +
theme(
legend.position = c(0.85, 0.5),
legend.background = element_rect(color = "white")
)
Let’s take a similar approach and sum up the facility occupancy each month
shelters %>%
group_by(
month = month(occupancy_date,
abbr = TRUE,
label = TRUE
),
year = factor(year(occupancy_date),
levels = c("2019", "2018", "2017")
), facility_name
) %>%
summarize(
tot_occupancy = mean(occupancy, na.rm = TRUE),
.groups = "drop_last"
) %>%
summarize(
tot_occupancy = sum(tot_occupancy),
.groups = "drop"
) %>%
ggplot(aes(month, tot_occupancy, color = year, group = year)) +
geom_line(size = 2) +
scale_y_continuous(label = scales::comma_format()) +
scale_x_discrete(expand = c(0, 0)) +
labs(
title = "Monthly Total Occupancy in Toronto's Homeless Shelter System",
y = NULL,
x = NULL, color = NULL,
caption = "Data: open.toronto.ca | Visual: jim_gruman"
) +
theme(
legend.position = c(0.9, 0.5),
legend.background = element_rect(color = "white")
)
Essentially dividing the occupancy by the capacity, this is the aggregated result as a percentage rate:
shelters %>%
group_by(
month = month(occupancy_date,
abbr = TRUE,
label = TRUE
),
year = factor(year(occupancy_date),
levels = c("2019", "2018", "2017")
),
facility_name
) %>%
summarize(
avg_occupancy = mean(occupancy, na.rm = TRUE),
avg_cap = mean(capacity, na.rm = TRUE),
.groups = "drop_last"
) %>%
summarize(
mean_rate = sum(avg_occupancy, na.rm = TRUE) / sum(avg_cap, na.rm = TRUE),
.groups = "drop"
) %>%
filter(year != "2017") %>%
ggplot(aes(month, mean_rate, color = year, group = year)) +
geom_line(size = 2) +
scale_y_continuous(label = scales::percent_format(accuracy = 1)) +
scale_x_discrete(expand = c(0, 0)) +
labs(
title = "Mean Occupancy Rate in Toronto's Homeless Shelter System",
subtitle = "Across the network, for the sum of all facilities",
y = NULL,
x = NULL,
caption = "Data: open.toronto.ca | Visual: jim_gruman"
) +
theme(
legend.position = c(0.9, 0.1),
legend.background = element_rect(color = "white")
)
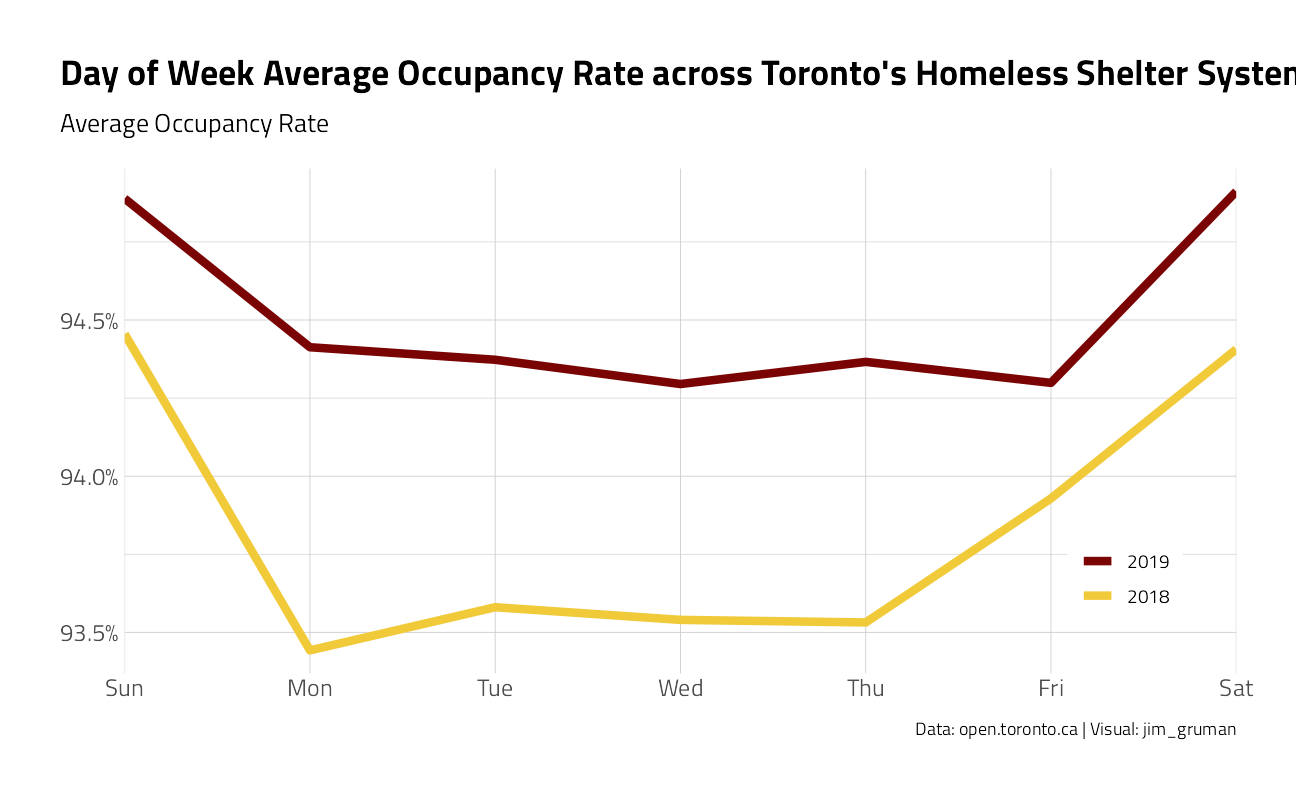
What about by day of the week ?
shelters %>%
mutate(
wday = wday(occupancy_date,
label = TRUE,
abbr = TRUE
),
year = year(occupancy_date)
) %>%
group_by(year, wday) %>%
summarise(
occupancy = sum(occupancy, na.rm = TRUE),
capacity = sum(capacity, na.rm = TRUE),
rate = occupancy / capacity,
.groups = "drop"
) %>%
filter(year %in% c(2018, 2019)) %>%
ggplot(aes(wday, rate,
color = factor(year,
levels = c("2019", "2018")
),
group = year
)) +
geom_line(size = 2) +
scale_x_discrete(expand = c(0, 0)) +
scale_y_continuous(labels = scales::percent_format(accuracy = .1)) +
labs(
title = "Day of Week Average Occupancy Rate across Toronto's Homeless Shelter System", y = NULL, x = NULL,
subtitle = "Average Occupancy Rate",
caption = "Data: open.toronto.ca | Visual: jim_gruman", color = NULL
) +
theme(
legend.position = c(0.9, 0.2),
legend.background = element_rect(color = "white")
)
The aggregate like might be misleading. What is the distribution of rates across the network each month?
shelters %>%
group_by(
month = month(occupancy_date,
abbr = TRUE,
label = TRUE
),
year = factor(year(occupancy_date),
levels = c("2019", "2018", "2017")
),
organization_name, facility_name
) %>%
summarize(
avg_occupancy = mean(occupancy, na.rm = TRUE),
avg_cap = mean(capacity, na.rm = TRUE),
.groups = "drop_last"
) %>%
filter(year != "2017", avg_occupancy > 0) %>%
mutate(
mean_rate = avg_occupancy / avg_cap,
CityShelter = if_else(organization_name == "City of Toronto", "City Shelter", "All Others")
) %>%
ggplot(aes(month, mean_rate, group = month)) +
geom_boxplot(outlier.alpha = 0.001) +
geom_jitter(aes(shape = CityShelter),
alpha = 0.7, size = 2, color = ipsum_pal()(2)[2]
) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_x_discrete(expand = c(0, 0)) +
labs(
title = "Mean Occupancy Rate for each Facility in Toronto's Homeless Shelter System",
subtitle = "Across the network, each month",
y = NULL,
x = NULL, shape = NULL,
caption = "Data: open.toronto.ca | Visual: jim_gruman"
) +
theme(
legend.position = c(0.9, 0.9),
legend.background = element_rect(color = "white")
)
Some facilities are nearly always over capacity every month. Many report exactly 100% occupancy every month.
How many facilities are managed by each organization?
shelters %>%
select(organization_name, facility_name) %>%
distinct(facility_name, .keep_all = TRUE) %>%
count(organization_name, sort = TRUE) %>%
mutate(organization_name = fct_reorder(organization_name, n)) %>%
ggplot(aes(n, organization_name)) +
geom_col(aes(fill = 4),
show.legend = FALSE
) +
labs(
title = "Toronto Homeless Shelter Organizations",
x = "Number of Facilities", y = "",
caption = "Data: open.toronto.ca | Visual: jim_gruman"
) +
theme(panel.grid.major.y = element_blank())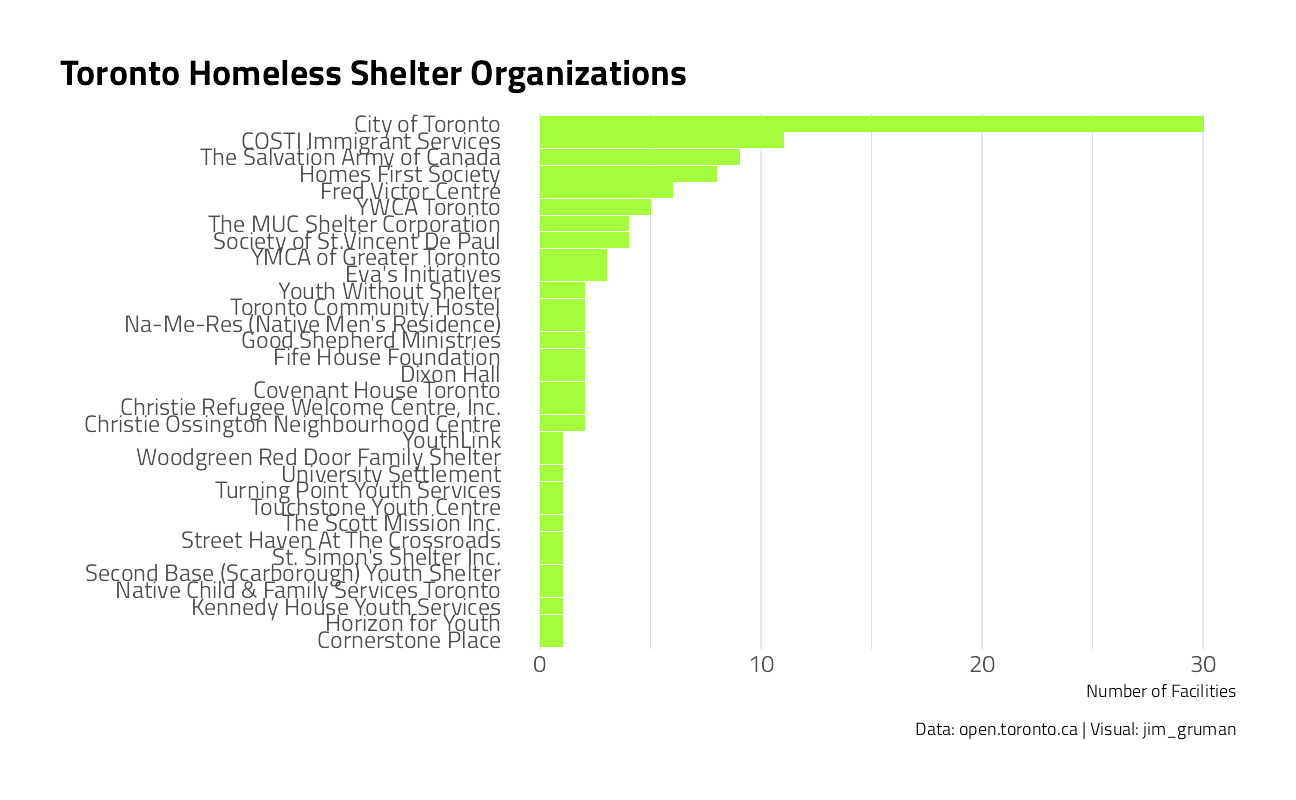
Let’s join the data frames of the weather with the shelter occupancy data by date
shelterWeather <- shelters %>%
filter(!is.na(occupancy)) %>%
filter(capacity > 0) %>%
filter(occupancy_date >= min(weather$date)) %>%
mutate(rate = occupancy / capacity) %>%
select(
id, organization_name, shelter_name, facility_name,
occupancy_date,
occupancy,
capacity,
rate
) %>%
left_join(weather, by = c("occupancy_date" = "date")) %>%
mutate(
precipitation_deg = case_when(
precipitation == 0 ~ "None",
between(precipitation, 0.01, 10) ~ "Low",
between(precipitation, 10.01, 20) ~ "Medium",
between(precipitation, 20.01, 40) ~ "High",
TRUE ~ "Very High"
),
org = case_when(
organization_name == "City of Toronto" ~ "City of Toronto",
TRUE ~ "All Others"
)
)What other patterns do we see each day?
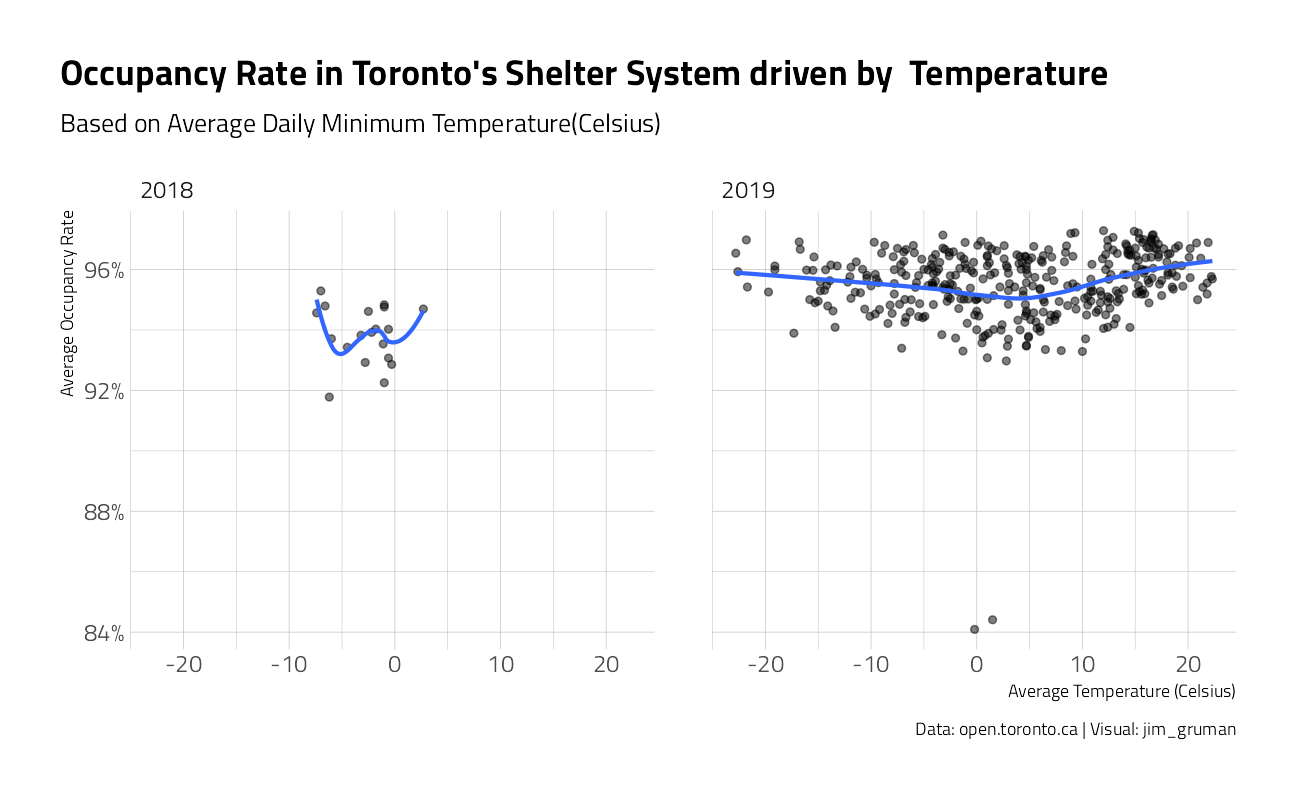
Let’s start with the minimum temperature. Note that the weather file earliest data is March of 2018.
shelterWeather %>%
group_by(
day = day(occupancy_date),
month = month(occupancy_date),
year = year(occupancy_date)
) %>%
summarise(
avg_rate = mean(rate, na.rm = TRUE),
avg_temp = mean(min_temperature, na.rm = TRUE),
avg_precipitation = mean(precipitation, na.rm = TRUE),
.groups = "drop"
) %>%
filter(year %in% c(2018, 2019)) %>%
ggplot(aes(avg_temp, avg_rate)) +
geom_point(alpha = 0.5) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
geom_smooth(se = FALSE) +
facet_wrap(~year) +
labs(
title = "Occupancy Rate in Toronto's Shelter System driven by Temperature",
subtitle = "Based on Average Daily Minimum Temperature(Celsius)",
y = "Average Occupancy Rate",
x = "Average Temperature (Celsius)",
caption = "Data: open.toronto.ca | Visual: jim_gruman"
)
shelterWeather %>%
filter(precipitation > 0) %>%
group_by(
day = day(occupancy_date),
month = month(occupancy_date),
year = year(occupancy_date)
) %>%
summarise(
avg_rate = mean(rate, na.rm = TRUE),
avg_temp = mean(min_temperature, na.rm = TRUE),
avg_precipitation = mean(precipitation, na.rm = TRUE),
.groups = "drop"
) %>%
filter(year %in% c(2018, 2019)) %>%
ggplot(aes(avg_precipitation, avg_rate)) +
geom_point(alpha = 0.5) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_x_log10() +
geom_smooth(se = FALSE) +
facet_wrap(~year) +
labs(
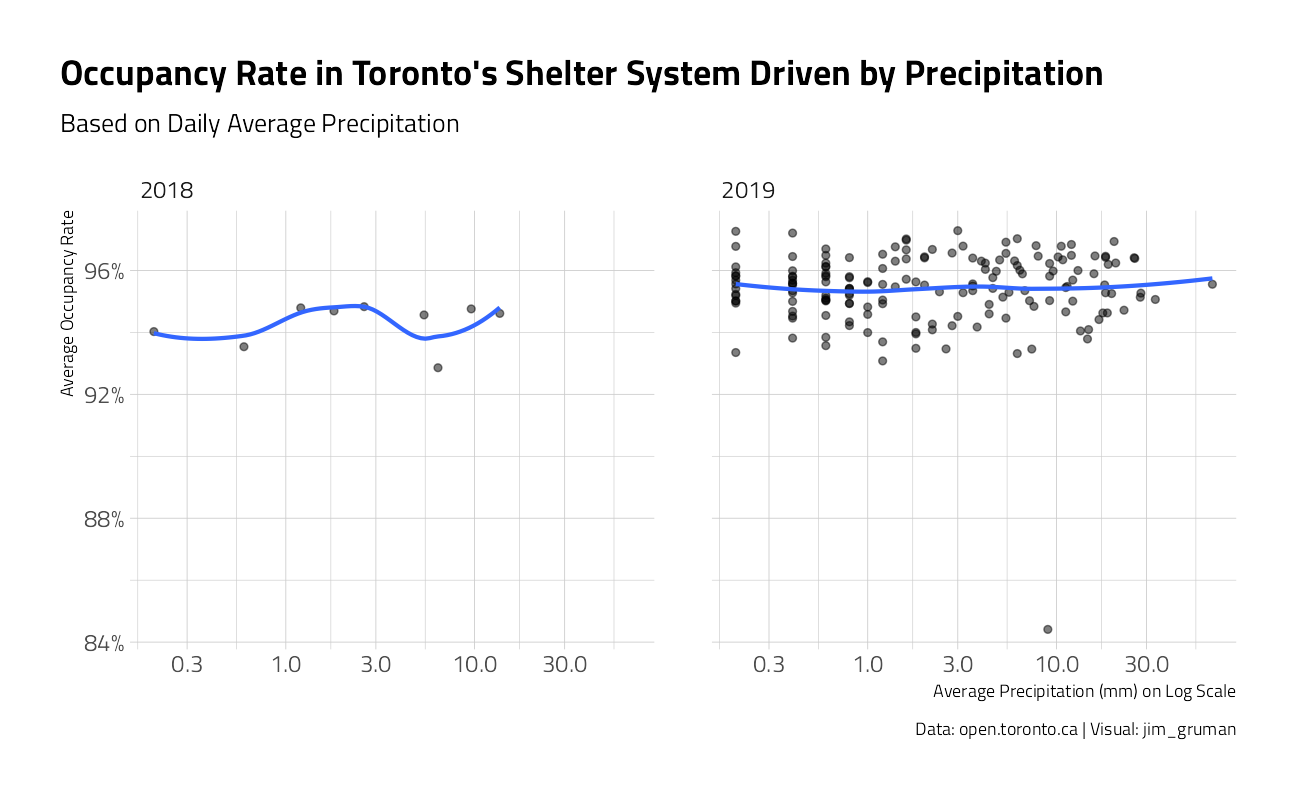
title = "Occupancy Rate in Toronto's Shelter System Driven by Precipitation",
subtitle = "Based on Daily Average Precipitation",
y = "Average Occupancy Rate",
x = "Average Precipitation (mm) on Log Scale",
caption = "Data: open.toronto.ca | Visual: jim_gruman"
)
Lets build a model of Over-Capacity events at each facility with features for the weekday, month, temperature, precipitation, and the two level org identifying the city shelters to make some inferences about what might be drivers of overcrowding.
Setting the breakpoint for over capacity at 0.999 could be argued because every shelter should have 1 empty bed for newcomers. It yields a data set that is largely balanced between response classes.
shelter_df <- shelterWeather %>%
mutate(over_cap = factor(if_else(rate > 0.9999, "Yes", "No"))) %>%
select(
over_cap, occupancy_date,
min_temperature,
precipitation_deg,
org
)
table(shelter_df$over_cap)
No Yes
16828 24493 shelter_rec <-
recipe(over_cap ~ ., data = shelter_df) %>%
step_date(occupancy_date,
features = c("dow", "month")
) %>%
step_holiday(occupancy_date,
holidays = timeDate::listHolidays("CA")
) %>%
step_rm(occupancy_date) %>%
step_dummy(all_nominal(), -all_outcomes()) %>%
step_center(all_predictors()) %>%
step_scale(all_predictors()) %>%
step_zv(all_predictors())
glm_mod <- logistic_reg() %>%
set_engine("glm") %>%
set_mode("classification")
shelter_wflow <- workflow() %>%
add_model(glm_mod) %>%
add_recipe(shelter_rec)Let’s fit the linear model
shelter_glmfit <-
shelter_wflow %>%
fit(data = shelter_df)This shelter_glmfit object has the finalized recipe and fitted model objects inside. Let’s extract the model objects from the workflow.
For over capacity events, what features can we infer may be significant?
shelter_glmfit %>%
tidy(conf.int = TRUE, exponentiate = TRUE) %>%
filter(term != "(Intercept)") %>%
mutate(term = fct_reorder(term, estimate)) %>%
ggplot(aes(estimate, term)) +
geom_point() +
geom_errorbarh(aes(xmin = conf.low, xmax = conf.high), color = "gray") +
geom_vline(xintercept = 1, color = "red") +
labs(
title = "Relative risk factors for Shelter Facility Overcapacity",
caption = "Data: open.toronto.ca | Visual: jim_gruman",
x = "Exponentiated estimate for log odds", y = NULL
)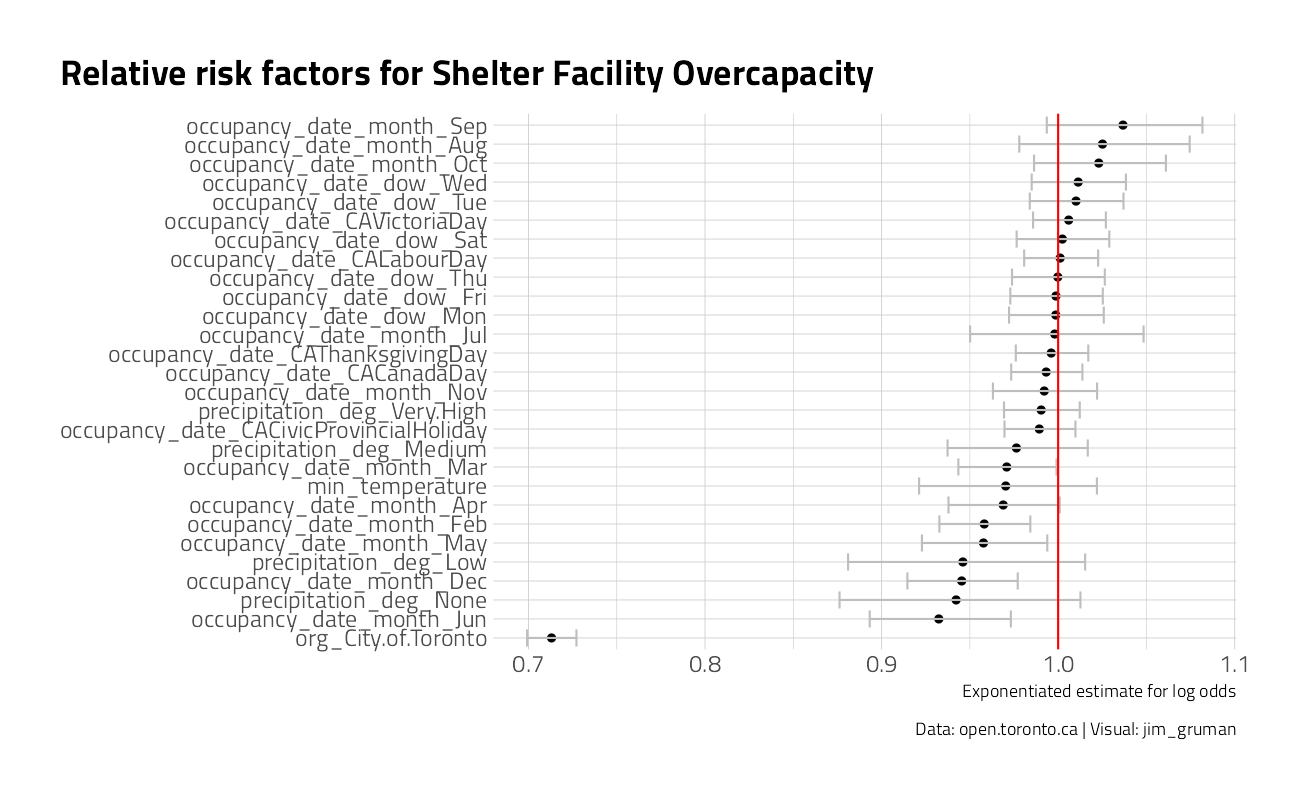
There is some evidence in this dataset that the months of December, (January), February, March, April, May, and June drive over occupancy over capacity. Also, the City of Toronto facilities themselves are over capacity.
My tweet from the archives:
tweetrmd::include_tweet("https://twitter.com/jim_gruman/status/1334250855319687175")Two for #TidyTuesday
— Jim Gruman📚🚵♂️⚙ (@jim_gruman) December 2, 2020
1) A treemap of organization/shelter/facility capacity
2) Inference of features that may drive over-capacityhttps://t.co/4ebkC4p5DP pic.twitter.com/rh4U79vGxr
sessionInfo()R version 4.1.1 (2021-08-10)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19043)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252
[2] LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] yardstick_0.0.8 workflowsets_0.1.0 workflows_0.2.3 tune_0.1.6
[5] rsample_0.1.0 recipes_0.1.16 parsnip_0.1.7.900 modeldata_0.1.1
[9] infer_1.0.0 dials_0.0.9.9000 scales_1.1.1 broom_0.7.9
[13] tidymodels_0.1.3 treemap_2.4-3 hrbrthemes_0.8.0 lubridate_1.7.10
[17] forcats_0.5.1 stringr_1.4.0 dplyr_1.0.7 purrr_0.3.4
[21] readr_2.0.1 tidyr_1.1.3 tibble_3.1.4 ggplot2_3.3.5
[25] tidyverse_1.3.1 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] readxl_1.3.1 backports_1.2.1 systemfonts_1.0.2
[4] selectr_0.4-2 plyr_1.8.6 igraph_1.2.6
[7] tidytuesdayR_1.0.1 splines_4.1.1 listenv_0.8.0
[10] usethis_2.0.1 gridBase_0.4-7 digest_0.6.27
[13] foreach_1.5.1 htmltools_0.5.2 viridis_0.6.1
[16] fansi_0.5.0 magrittr_2.0.1 tzdb_0.1.2
[19] globals_0.14.0 modelr_0.1.8 gower_0.2.2
[22] extrafont_0.17 vroom_1.5.4 R.utils_2.10.1
[25] extrafontdb_1.0 hardhat_0.1.6 colorspace_2.0-2
[28] rvest_1.0.1 textshaping_0.3.5 haven_2.4.3
[31] xfun_0.25 crayon_1.4.1 jsonlite_1.7.2
[34] survival_3.2-11 iterators_1.0.13 glue_1.4.2
[37] gtable_0.3.0 ipred_0.9-11 R.cache_0.15.0
[40] tweetrmd_0.0.9 Rttf2pt1_1.3.9 future.apply_1.8.1
[43] DBI_1.1.1 Rcpp_1.0.7 viridisLite_0.4.0
[46] xtable_1.8-4 bit_4.0.4 GPfit_1.0-8
[49] lava_1.6.10 prodlim_2019.11.13 httr_1.4.2
[52] RColorBrewer_1.1-2 ellipsis_0.3.2 farver_2.1.0
[55] R.methodsS3_1.8.1 pkgconfig_2.0.3 nnet_7.3-16
[58] sass_0.4.0 dbplyr_2.1.1 utf8_1.2.2
[61] here_1.0.1 labeling_0.4.2 tidyselect_1.1.1
[64] rlang_0.4.11 DiceDesign_1.9 later_1.3.0
[67] munsell_0.5.0 cellranger_1.1.0 tools_4.1.1
[70] cachem_1.0.6 cli_3.0.1 generics_0.1.0
[73] evaluate_0.14 fastmap_1.1.0 yaml_2.2.1
[76] ragg_1.1.3 bit64_4.0.5 knitr_1.33
[79] fs_1.5.0 nlme_3.1-152 future_1.22.1
[82] whisker_0.4 mime_0.11 R.oo_1.24.0
[85] xml2_1.3.2 compiler_4.1.1 rstudioapi_0.13
[88] curl_4.3.2 reprex_2.0.1 lhs_1.1.1
[91] bslib_0.3.0 stringi_1.7.4 highr_0.9
[94] gdtools_0.2.3 lattice_0.20-44 Matrix_1.3-4
[97] styler_1.5.1 conflicted_1.0.4 vctrs_0.3.8
[100] pillar_1.6.2 lifecycle_1.0.0 furrr_0.2.3
[103] jquerylib_0.1.4 data.table_1.14.0 httpuv_1.6.2
[106] R6_2.5.1 promises_1.2.0.1 gridExtra_2.3
[109] parallelly_1.27.0 codetools_0.2-18 MASS_7.3-54
[112] assertthat_0.2.1 rprojroot_2.0.2 withr_2.4.2
[115] mgcv_1.8-36 parallel_4.1.1 hms_1.1.0
[118] grid_4.1.1 rpart_4.1-15 timeDate_3043.102
[121] class_7.3-19 rmarkdown_2.10 git2r_0.28.0
[124] pROC_1.18.0 shiny_1.6.0